- Infini AI
- Posts
- 4 Popular Machine Learning Algorithms
4 Popular Machine Learning Algorithms
Mark Jedidaiah Raj
August 09, 2024
Dear Readers
In recent years, Machine Learning (ML) has transitioned from a niche topic in data science to a critical element in nearly every industry. From healthcare to finance, ML is transforming how we approach complex problems and make decisions. This newsletter introduces four of the most popular machine learning algorithms that drive innovation today. Whether you're new to ML or just looking to refresh your knowledge, this guide will help you understand these foundational algorithms.
1. Linear Regression
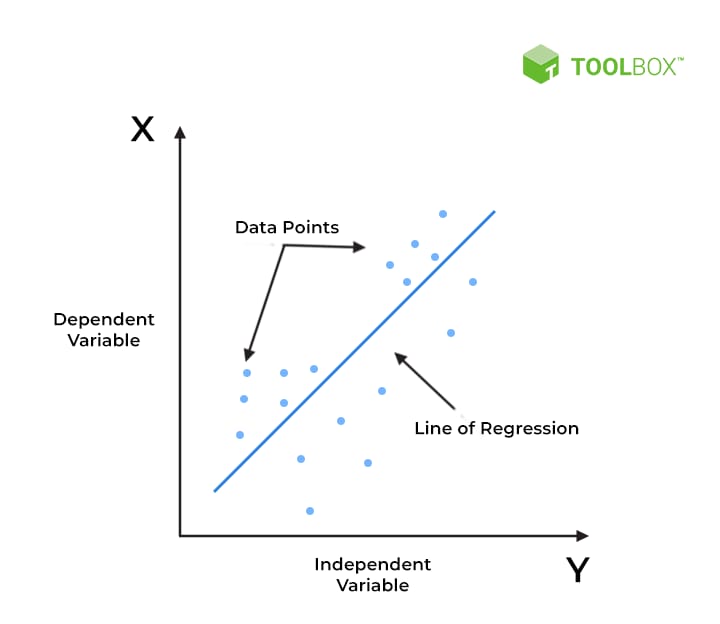
Overview: Linear Regression is one of the simplest and most well-known algorithms in machine learning. It's used for predicting a continuous variable (often called the dependent variable) based on the value of one or more independent variables.
How It Works: Linear regression assumes a linear relationship between the input variables (X) and the output variable (Y). The algorithm fits a straight line (the regression line) through the data points in such a way that the distance between the data points and the line is minimized.
Use Cases:
Predicting housing prices based on features like square footage, number of bedrooms, etc.
Estimating sales figures based on advertising spend.
Key Takeaway: Linear Regression is perfect for scenarios where the relationship between variables is expected to be linear. It's simple, interpretable, and often the first algorithm to try when dealing with regression problems.
2. Decision Trees
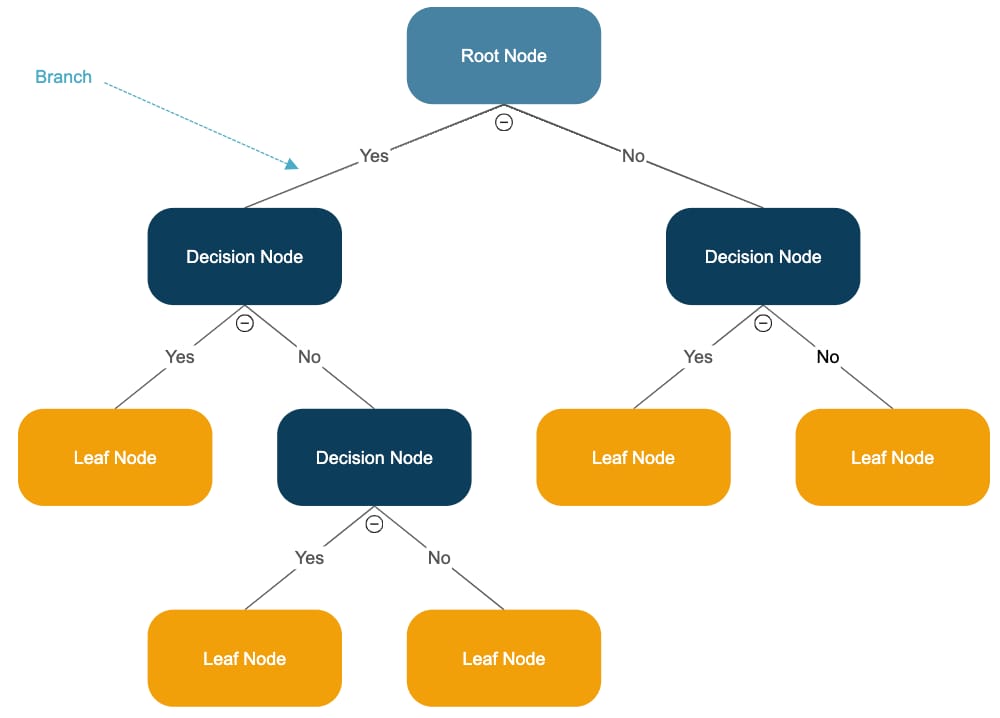
Overview: Decision Trees are a powerful, intuitive method for both classification and regression tasks. They work by splitting the data into subsets based on the value of input variables, forming a tree-like structure.
How It Works: The algorithm starts at a root node and splits the data into branches based on specific decision criteria (e.g., "Is the temperature greater than 20°C?"). This process continues until the algorithm reaches a decision or prediction at a leaf node.
Use Cases:
Diagnosing diseases based on symptoms.
Credit scoring and loan approval processes.
Key Takeaway: Decision Trees are easy to interpret and can handle both numerical and categorical data. They're especially useful when you need a clear and understandable model.
3. k-Nearest Neighbors (k-NN)

Overview: k-Nearest Neighbors is a simple, non-parametric algorithm used for classification and regression. It operates on the principle that similar things exist in close proximity to each other.
How It Works: When making a prediction, k-NN looks at the 'k' closest data points (neighbors) in the training dataset and makes predictions based on the majority vote for classification or average for regression.
Use Cases:
Image recognition, such as handwriting detection.
Recommender systems for personalized suggestions.
Key Takeaway: k-NN is easy to implement and works well with small datasets, but it can be computationally intensive with large datasets. It’s a great choice when simplicity and direct similarity measures are important.
4. Support Vector Machines (SVM)

Overview: Support Vector Machines are powerful algorithms typically used for classification tasks, though they can also be used for regression. SVMs are particularly effective in high-dimensional spaces and are known for their robustness.
How It Works: SVM finds the optimal hyperplane that separates data points of different classes with the maximum margin. In cases where data isn’t linearly separable, SVM uses a technique called the kernel trick to map the data into a higher-dimensional space where it becomes separable.
Use Cases:
Text classification, such as spam detection.
Face detection in images.
Key Takeaway: SVMs are versatile and effective for complex classification problems, particularly when the data is not linearly separable. They tend to work well even with a limited number of samples.
Conclusion
Machine Learning offers a wide array of algorithms to tackle different types of problems. The four algorithms discussed—Linear Regression, Decision Trees, k-Nearest Neighbors, and Support Vector Machines—form a solid foundation for anyone looking to delve deeper into the world of ML. Each algorithm has its strengths and is suited to particular types of tasks, making them indispensable tools in the machine learning toolkit.
Machine learning is not about replacing human jobs; it's about augmenting human capabilities. These algorithms are designed to handle specific tasks that would be challenging or time-consuming for humans, freeing us to focus on creativity and innovation.
Machine learning is an ever-evolving field, and staying up-to-date with the latest advancements is crucial. Keep experimenting, stay curious, and remember that the best way to learn is by doing.
Until next time,
MJR
For those wondering who am I to share or write on this, my name is Mark Jedidaiah Raj and I am an AI Specialist, AI Architect, AI Coach, AI Consultant and an author. My research work and work experience has given me knowledge and exposure to share quality knowledge with knowledge seekers such as you, friend. Have a good one and keep breaking records mate.
TikTok id : @aimastermind_mjr
YouTube id : @aimastermind_mjr
Website : https://www.mjris.com/
Reach me at https://beacons.ai/aimastermind
Alternatively, you can type
“Mark Jedidaiah Raj”
on either platforms and my videos on AI will help excite your journey in AI.
Reply